git是linus开发的一款版本控制工具,大神的作品果然不同凡响,git正在变得越来越流行。
在使用的过程中,也感觉到其易用和高效。因此想要探究一下其内部的原理。
git的高效得益于其存储系统的实现,它是一个内容寻址的文件系统。git的核心是一个键值数据库,你可以向这个数据库中插入任意类型的内容,它会返回一个键值作为唯一标识,通过该键值你可以检索插入的数据。我们来通过一个例子理解一下:
我们创建一个测试库
$ git init test
Initialized empty Git repository in U:/git/git-study/test/.git/
git会在test目录下创建一个.git目录,里面有一个objects目录,这就是数据库存储所有对象的地方,可以看到现在是空的。
$ find .git/objects/ -type f
现在我们存储一个数据对象
$ echo ‘test content’ git hash-object -w –stdin
d670460b4b4aece5915caf5c68d12f560a9fe3e4
通过上面的命令将’test content’存入对象数据库,存入成功后git给我们返回了一个键值。
–stdin表示从标准输入读入要存储的对象
-w表示将对象存入到对象数据库
再来看下对象数据库目录的变化
$ find .git/objects -type f
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4
可以看到存入了我们刚才创建的对象,
git会将待存储的数据外加一个头部信息(header)一起做 SHA-1 校验运算得到一个摘要。后文会简要讨论该头部信息。 摘要为40个字节,git用前2个字节作为子目录,后38个字节作为文件名,这样增加了一级索引能够加快查找。
git中的所有对象文件都可以用cat-file命令来查看,”-t”查看对象文件的类型,”-p”查看对象文件的内容,我们来看一下。
$ git cat-file -t d670
blob
通过”-t”选项可以看到这个对象文件是一个blob,后面会介绍git中的几种对象。
$ git cat-file -p d670
test content
通过”-p”选项可以查看文件内容,注意我们只指定了SHA-1摘要的前4个字节,只要能够唯一区分就可以,无需全部指出。
直接存储内容,用sha值来获取并不现实。因此我们需要文件名,我们再来看下git如何存储文件名。
我们创建一个’test content’内容的文件,再把它提交到git中,看看有什么变化。
$ echo ‘test content’ > test.txt
$ git add .
$ git commit -m “add test.txt”
add test.txt
1 file changed, 1 insertion(+)
create mode 100644 test.txt
我们再来看下对象库里的文件
$ find .git/objects/
.git/objects/
.git/objects/80
.git/objects/80/865964295ae2f11d27383e5f9c0b58a8ef21da
.git/objects/d6
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4
.git/objects/e3
.git/objects/e3/b5f9d4884c0f93d3f9c69e6a94cee29c9d94b2
.git/objects/info
.git/objects/pack
可以看到里面多了2个对象,我们用cat-file命令来探究一下。
$ git cat-file -t 8086
tree
$ git cat-file -t e3b5
commit
可以看到一个对象类型为’tree’,另一个对象类型为’commit’.
我们再来看看对象的内容:
$ git cat-file -p e3b5
tree 80865964295ae2f11d27383e5f9c0b58a8ef21da
author happyAnager6 happyAnger6@163.com 1565186367 +0800
committer happyAnager6 happyAnger6@163.com 1565186367 +0800
add test.txt
这个commit的SHA值和git log里看到的是一致的
$ git log
commit e3b5f9d4884c0f93d3f9c69e6a94cee29c9d94b2
Author: happyAnager6 happyAnger6@163.com
Date: Wed Aug 7 21:59:27 2019 +0800
$ git cat-file -p 8086
100644 blob d670460b4b4aece5915caf5c68d12f560a9fe3e4 test.txt
可以看commit对象里包含了这个tree,并且还有作者和提交者以及提交注释。
tree对象里是test.txt文件名和其引用的blob对象。
我们可以得到下面的关系图:
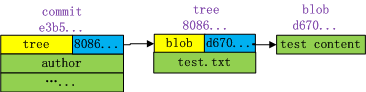
到这里,我们可以学习到git里的3种对象,commit,tree,blob
commit对象存储的是提交点,里面包含提交的顶层tree对象.
tree对象用于表示文件系统中的文件和目录,存储文件名称和引用的blob对象。
blob对象用于存储实际的数据。
tree和blob模拟出了LINUX里文件系统的概念,tree类似于是dentry目录项,blob类似于是inode。
了解了git中几种对象各自的作用,我们再来看一下git存储实现的高效。
我们再创建一个test1.txt,文件内容和test.txt一样,那么提交后的对象数据库会怎样变化呢?
$ echo “test content” >> test1.txt
$ git add .
$ git commit -m “add test1.txt”
add test1.txt
1 file changed, 1 insertion(+)
create mode 100644 test1.txt
添加好后,我们再来看下对象库的内容。
$ find .git/objects/ -type f
.git/objects/41/402111639cba891703ae9b82e1cf92171f1418
.git/objects/76/7b3496b30214180609a493bbf8130012a4ef30
.git/objects/80/865964295ae2f11d27383e5f9c0b58a8ef21da
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4
.git/objects/e3/b5f9d4884c0f93d3f9c69e6a94cee29c9d94b2
可以看到多了2个对象,我们再用cat-file看一下
$ git cat-file -t 4140
commit
$ git cat-file -t 767b
tree
$ git cat-file -p 4140
tree 767b3496b30214180609a493bbf8130012a4ef30
parent e3b5f9d4884c0f93d3f9c69e6a94cee29c9d94b2
author happyAnager6 happyAnger6@163.com 1565188008 +0800
committer happyAnager6 happyAnger6@163.com 1565188008 +0800
add test1.txt
$ git cat-file -p 767b
100644 blob d670460b4b4aece5915caf5c68d12f560a9fe3e4 test.txt
100644 blob d670460b4b4aece5915caf5c68d12f560a9fe3e4 test1.txt
我们再整理下这5个对象的关系图如下:
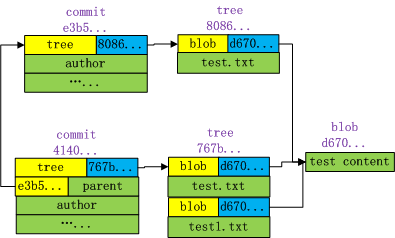
可以看到,新的commit对象是上一个commit对象的孩子,新的commit对象引用了一个新的tree对象,新的tree对象包含了2个blob对象的引用,存储了2个不同的文件名,由于文件内容相同,因此2个blob对象引用的是同一个blob对象。
通过上面这个例子,我们可以看到对于内容相同名字不同的文件,最终的文件内容只有一个blob对象,不同的文件通过引用来指向同一个blob。git就是这样使用指针来实现对象的高效复用的。
结合cat-file命令和上面介绍的3种对象你就可以分析git版本库对象存储的工作原理了,是不是有点儿feeling了?
最后再回答下对象存储的格式:
对象类型(blob,tree,commit)+空格+数据长度+NULL+内容